Hi Leute, war im Urlaub... Danke für die Feedbacks.
1. Nvidia Logo statt M1 ... wird zügig gefixt
2. VYSNC off beim Test etwas aufwändiger - evtl. sinnvoller gleich anderen, METAL basierenden Bench einzubauen statt OceanWave (mit bis zu 1500 FPS ;))
Jedoch Hauptgrund für Update der schon älteren App war update der Speedmessing PCIe und VRAM um die dort sehr guten M1 Werte abzubilden. Diese sind mit ein Grund weshalb diese Apple GPUs so zügig laufen - bei gleicher PCIe / VRAM Speed wie bei uns, PC/AMD sähen die Apple GPUs in manchen Anwendungen gar nicht mehr so gut aus.
EDIT:
Hi Leute,
statt OceanWave (opencl, Vsync limitiert) würde ich Nbody Metal als Speedmeter nehmen- ist unabhängig von Vsync, misst GigaFlops.
Testet die App mal bitte kurz ob die sowohl auf Midrange AMDs als auch M1 noch gut läuft.
Läuft 10 sec, beendet automatisch. Klar wird später das Ergebnis (Max Gigaflops) in der eigentlichen Bench App angezeigt, wie bei Oceanwave.
Ansonsten würde ich die Anzahl der Objekte (65K) etwas erniedrigen. Auf meiner RX 570 mit 5GB läuft sie noch rund - kann sein ne RX 560 ist bei der 80K Objektanzahl schon etwas laggy ..
RX 570 ca. 2800 Gigaflops (Min 2780 ....Max 2850)
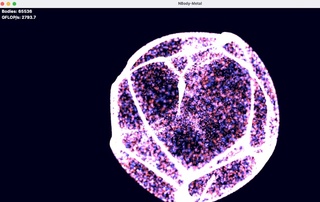
Wenn das bei Euch läuft ersetze ich die Oceanwave (Vysnc limittiert & old OpenCL) mit Gigaflops Nbody.
...
DL siehe Posting weiter unten, DL V2.3



